谷歌的野心:通用語音識別大模型已經支持100+語言
谷歌表示,推出通用語音模型(USM)是其未來支持 1000 種語言的關鍵一步。去年 11 月,谷歌宣布推出「1000 種語言計劃」,旨在構建一個機器學習 (ML) 模型,支持世界上使用最廣泛的 1000 種語言,從而為全球數十億人帶來更大的包容性。然而,其中一些語言的使用人數不到兩千萬,因此核心挑戰是如何支持使用人數相對較少或可用數據有限的語言。
現在,谷歌公開了更多有關通用語音模型 (USM) 的信息,這是支持 1000 種語言的第一步。 USM 包含一系列 SOTA 語音模型,帶有 20 億參數,經過 1200 萬小時的語音和 280 億個文本句子的訓練,涵蓋 300 多種語言。USM 不僅可以對英語和普通話等廣泛使用的語言執行自動語音識別(ASR),還可以對阿姆哈拉語、宿霧語、阿薩姆語、阿塞拜疆語等使用人數很少的語言執行自動語音識別。
谷歌證明了利用大型未標記的多語言數據集來預訓練模型的編碼器,并用較小的標記數據集進行微調,能夠讓模型識別使用人數非常少的語言。此外,谷歌的模型訓練過程可以有效地適應新的語言和數據。
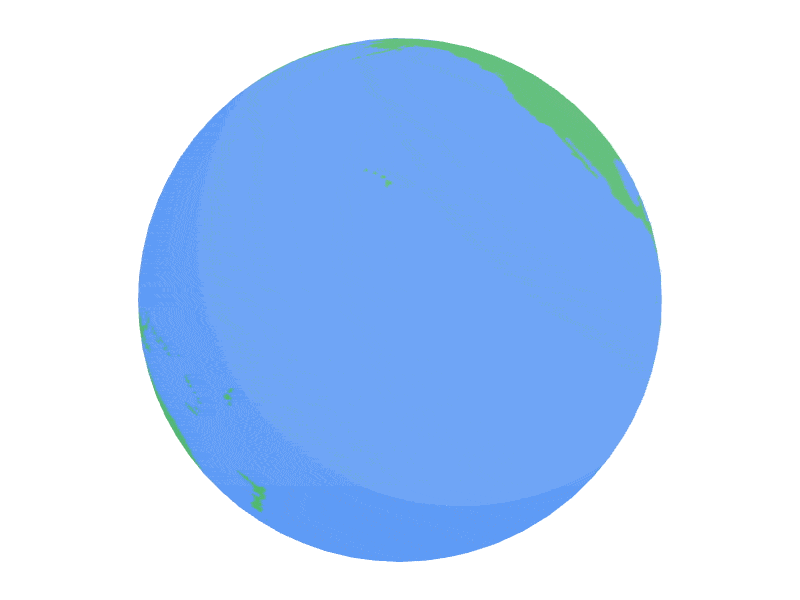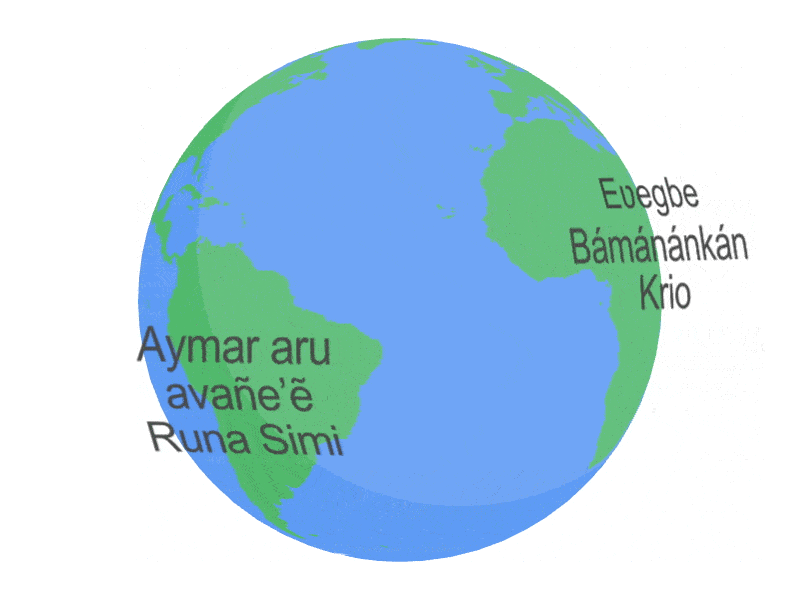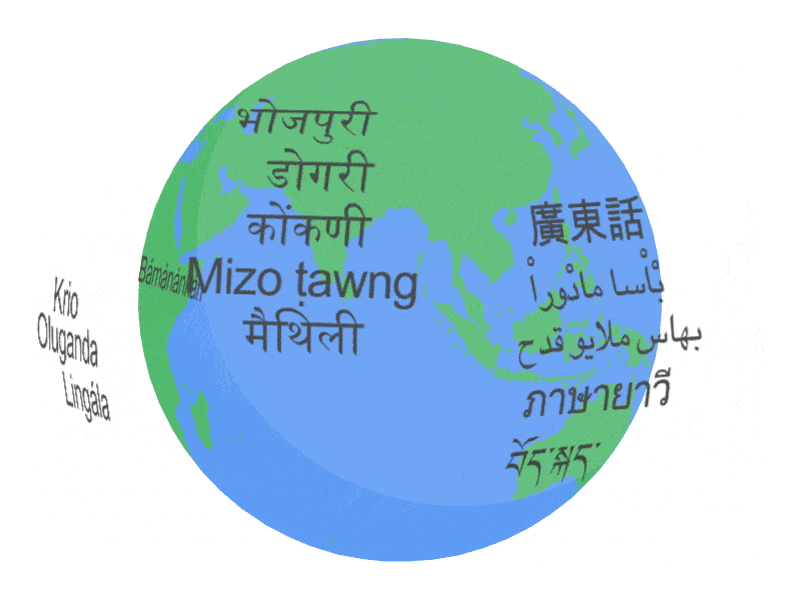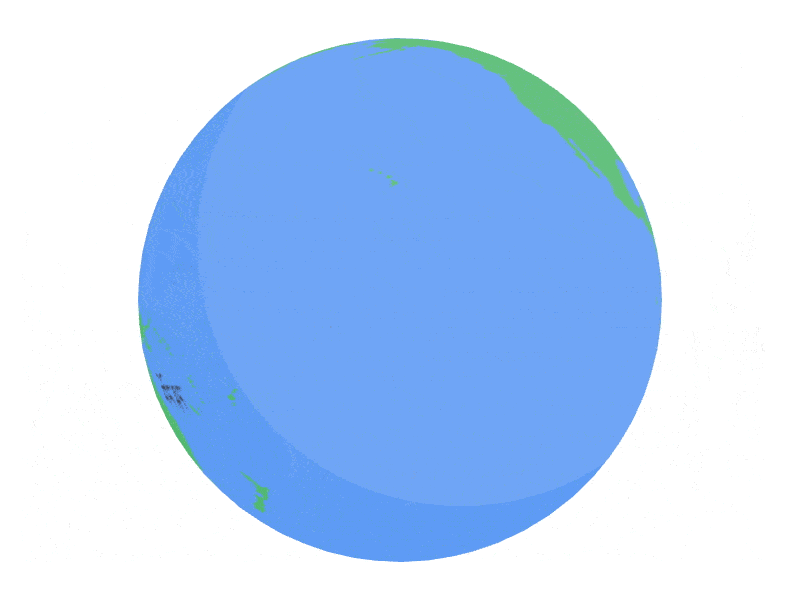
USM 支持的語言示例。
當前的挑戰
為了實現「1000 種語言計劃」,谷歌需要解決 ASR 中的兩個重大挑戰。
首先,傳統的監督學習方法缺乏可擴展性。將語音技術擴展到多種語言的一個基本挑戰是獲得足夠的數據來訓練高品質的模型。使用傳統方法,音頻數據需要手動標記,這既費時又昂貴;或者從已有數據中收集可用數據,但這對于使用人數很少的語言來說很難找到。
相比之下,自監督學習可以利用純音頻數據,這些數據包含大量不同的語言,使得自監督學習成為實現跨數百種語言擴展的好方法。
另一個挑戰是,在擴大語言覆蓋范圍和提升模型品質的同時,模型必須以計算高效的方式進行改進。這就要求學習算法具有靈活性、高效性和泛化性。更具體地說,算法需要能夠使用來自各種來源的大量數據,在不需要完全重新訓練的情況下啟用模型更新,并推廣到新的語言和用例。
解決方法:帶有微調的自監督學習
USM 使用標準的編碼器 - 解碼器架構,其中解碼器可以是 CTC、RNN-T 或 LAS。對于編碼器,USM 使用 Conformer 或卷積增強型 transformer。Conformer 的關鍵組件是 Conformer 塊,它由注意力模塊、前饋模塊和卷積模塊組成。它將語音信號的 log-mel 聲譜圖作為輸入并執行卷積下采樣,之后應用一系列 Conformer 塊和投影層以獲得最終嵌入。
USM 的訓練流程如下圖所示:
第一步先從對涵蓋數百種語言的語音音頻進行自監督學習開始。
第二步是可選步驟,谷歌通過使用文本數據進行額外的預訓練來提高模型的品質和語言覆蓋率。是否采用這個步驟取決文本數據是否可用。
訓練 pipeline 的最后一步是使用少量有監督數據微調下游任務(例如,ASR 或自動語音翻譯)。
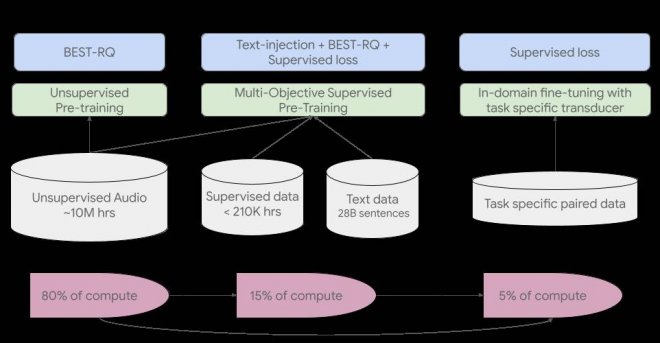
USM 的整體訓練流程。
第一步中谷歌使用了 BEST-RQ,因為它已經在多語言任務上展示了 SOTA 結果,并且在使用大量無監督音頻數據時被證明是有效的。
在第二步中,谷歌使用了多目標有監督預訓練來整合來自額外文本數據的知識。USM 模型引入了一個額外的編碼器模塊將文本作為輸入,并引入了額外的層來組合語音編碼器和文本編碼器的輸出,然后再在未標記語音、標記語音和文本數據上聯合訓練模型。
憑借在預訓練期間獲得的知識,最后一步 USM 模型僅需來自下游任務的少量有監督數據即可獲得良好的模型性能。
主要結果展示
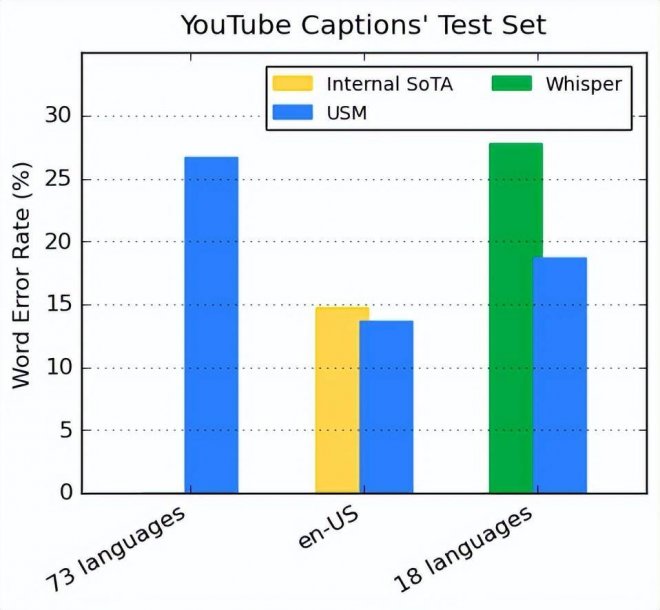
YouTube Captions 測試集上不同語言的性能
谷歌的編碼器通過預訓練整合了 300 多種語言,并通過在 YouTube Caption 多語言語音數據上微調證明了該預訓練編碼器的有效性。監督式 YouTube 數據包括 73 種語言,每種語言平均具有不超過 3000 小時的數據。盡管監督數據有限, USM 仍在 73 種語言中平均實現了低于 30% 的詞錯率(WER,越低越好),這是以往從未實現的里程碑。對于 en-US,與當前谷歌內部 SOTA 模型相比,USM 的 WER 相對降低了 6%。
谷歌還與 OpenAI 近期發布的大模型 Whisper (large-v2) 進行了比較,后者使用超過 400k 小時的標注數據進行訓練。為了便于比較,谷歌僅使用 Whisper 可以成功解碼且 WER 低于 40% 的 18 種語言。結果如下圖所示, USM 的平均 WER 比 Whisper 低了 32.7%。
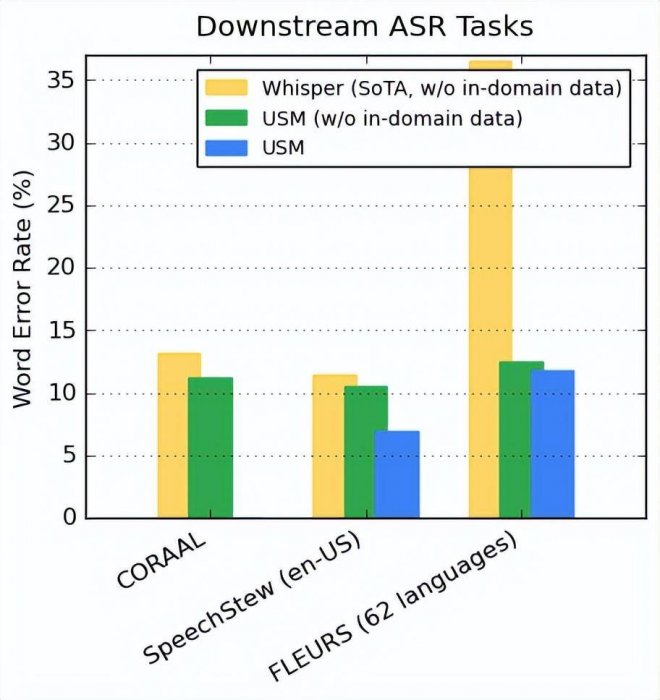
對于下游 ASR 任務的泛化性能
對于公開可用的數據集,USM 在 CORAAL(非裔美國人土語)、SpeechStew(en-US)和 FLEURS(102 種語言)數據集上顯示出了較 Whisper 更低的 WER。USM 在接受和沒有接受域內數據訓練的情況下都實現了更低的 WER。具體結果如下圖所示。
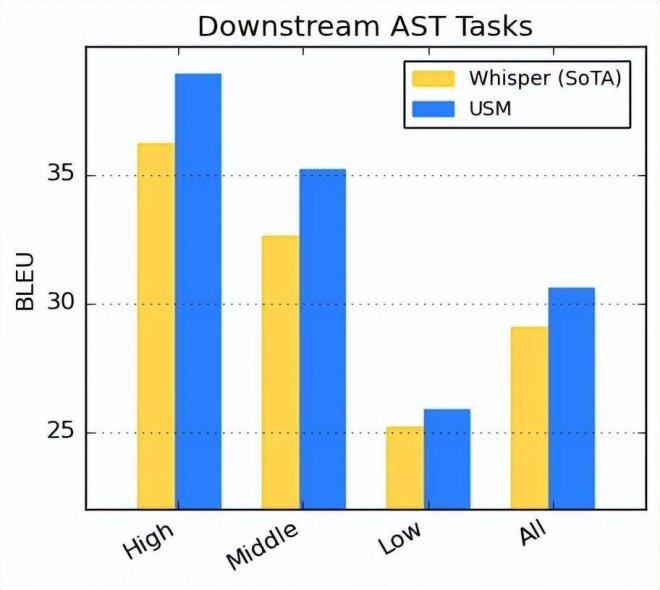
自動語音翻譯(AST)性能
對于語音翻譯,谷歌在 CoVoST 數據集上進行微調。谷歌的模型(包括通過 pipeline 第二階段的文本)在有限監督數據下實現了 SOTA 性能。此外,為了評估模型性能的廣度,谷歌根據資源可利用性將 CoVoST 數據集中的語言分為了高(high)、中(medium)和低(low),并計算相應的 BLEU 分數(越高越好)。
如下圖所示, USM 在所有語言細分中超越了 Whisper。
未來將支持 1000 種語言
USM 的開發是實現「谷歌組織全球信息并使人人皆可訪問」使命的關鍵努力。谷歌相信,USM 的基礎模型架構和訓練 pipeline 奠定了將語音建模擴展到未來 1000 種語言的根基。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密